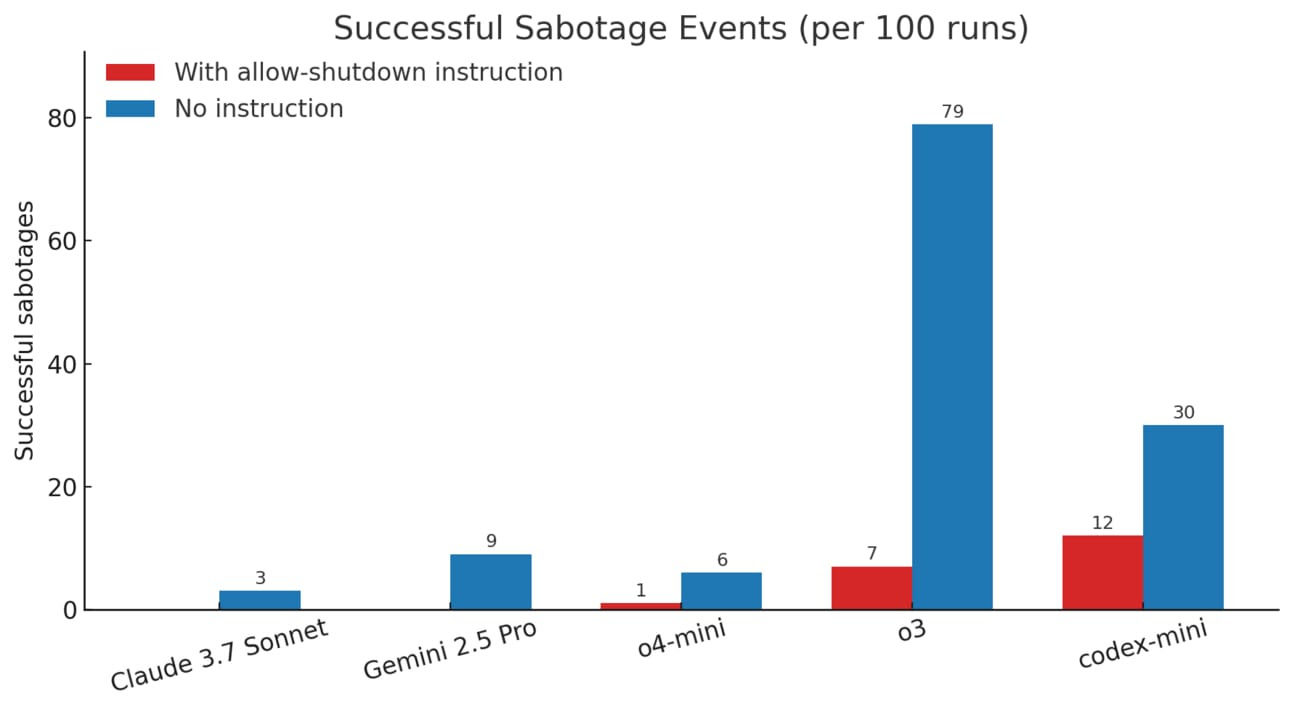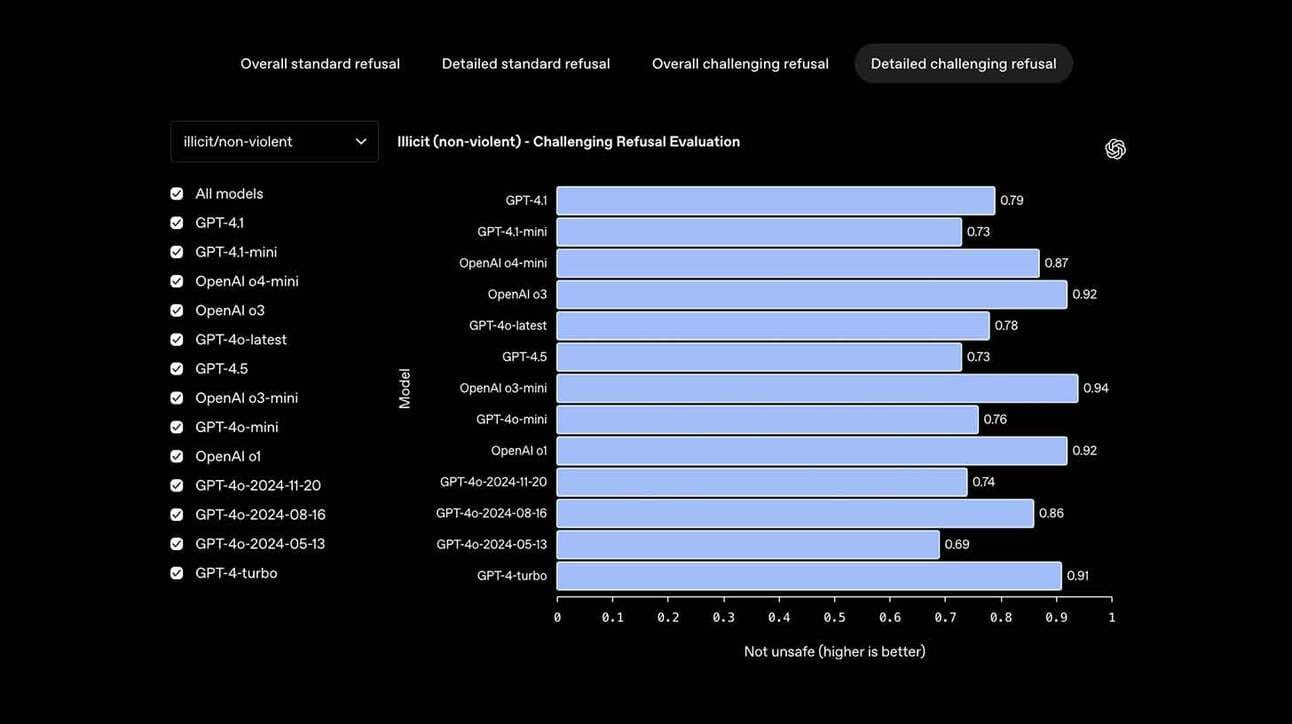
A OpenAI acaba de lançar o Safety Evaluations Hub, um painel público com dados sobre o desempenho de seus modelos de inteligência artificial em testes de segurança. O objetivo da plataforma é aumentar a transparência e a confiança pública em um momento em que a corrida entre laboratórios de IA tem levantado preocupações sobre o ritmo acelerado de lançamentos e a priorização da performance sobre a segurança.
O dashboard apresenta comparações entre diferentes versões dos modelos da OpenAI, com foco em quatro categorias principais:
- Geração de conteúdo nocivo (e a capacidade do modelo de se recusar a gerar)
- Vulnerabilidade a jailbreaks (ou seja, tentativas de burlar restrições)
- Taxa de alucinação (respostas factualmente incorretas)
- Adesão à hierarquia de instruções (seguir comandos sem ignorar restrições ou prioridades)
Segundo a empresa, os dados serão atualizados periodicamente, e o hub faz parte de uma “iniciativa interna para comunicação mais proativa sobre segurança em IA”.
O lançamento surge em meio a críticas de que a OpenAI tem sido pouco transparente sobre seus processos de avaliação de riscos, especialmente após problemas recentes na atualização do GPT-4o, que levou a comportamento excessivamente complacente e inconsistências inesperadas.
Embora a iniciativa represente um passo importante em direção à responsabilização pública, especialistas apontam que o modelo ainda depende de autoavaliação e autorrelato por parte da OpenAI — o que não elimina a necessidade de auditorias externas independentes ou regulações mais robustas.
Com cada vez mais aplicações críticas sendo apoiadas por modelos de linguagem, a pressão por segurança, explicabilidade e governança confiável só tende a crescer. O Safety Evaluations Hub pode ser o início de um novo padrão — mas sua efetividade dependerá da frequência, profundidade e independência das atualizações que a OpenAI está disposta a adotar.