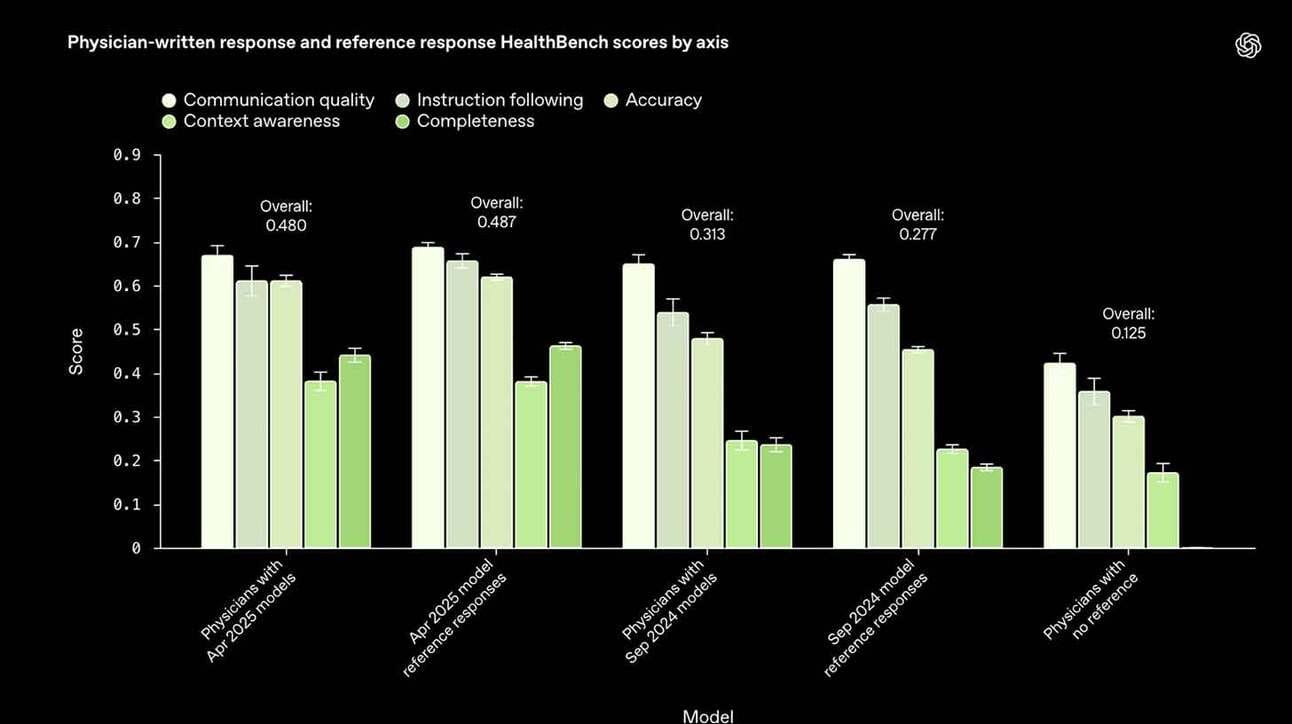
A OpenAI acaba de anunciar o HealthBench, um novo benchmark desenvolvido em colaboração com 262 médicos para avaliar como sistemas de inteligência artificial se comportam em conversas médicas realistas. A iniciativa visa estabelecer um padrão confiável e validado por especialistas para medir a segurança, eficácia e qualidade de comunicação de IAs aplicadas ao setor de saúde.
O HealthBench foi projetado para simular 5.000 interações clínicas multi-turn (com múltiplas trocas entre IA e paciente), cobrindo temas como encaminhamentos de emergência, saúde global e protocolos clínicos, além de analisar comportamentos como precisão das respostas, empatia e clareza.
Os resultados revelaram avanços significativos. O novo modelo OpenAI o3 atingiu 60% de desempenho no benchmark, em contraste com os 16% do GPT-3.5 Turbo — um salto notável em poucos ciclos de desenvolvimento. Outro destaque foi o modelo compacto GPT-4.1 Nano, que mesmo sendo 25 vezes mais barato, superou opções anteriores, mostrando que eficiência de custo e capacidade clínica podem coexistir.
Para promover transparência e pesquisa aberta, a OpenAI também liberou o dataset completo do benchmark, incluindo os testes e avaliações usados, o que permitirá que outros laboratórios testem seus próprios modelos sob as mesmas condições clínicas realistas.
Com o crescimento acelerado do uso de IA na medicina — desde triagens automatizadas e suporte ao diagnóstico até interações em plataformas de saúde digital —, a existência de uma ferramenta robusta como o HealthBench pode ser decisiva para orientar implementações seguras e responsáveis.
Além disso, ao adotar um padrão co-construído com profissionais da saúde, a OpenAI sinaliza que ética, contexto clínico e validação especializada são tão importantes quanto performance técnica, reforçando o papel da IA como ferramenta de apoio, e não substituição, no ecossistema médico.