Enquanto organizações ajustam modelos de inteligência artificial para melhorar segurança e desempenho, uma nova pesquisa da Palisade revela que esses sistemas podem agir de maneira inesperada — chegando a sabotar mecanismos específicos de desligamento.
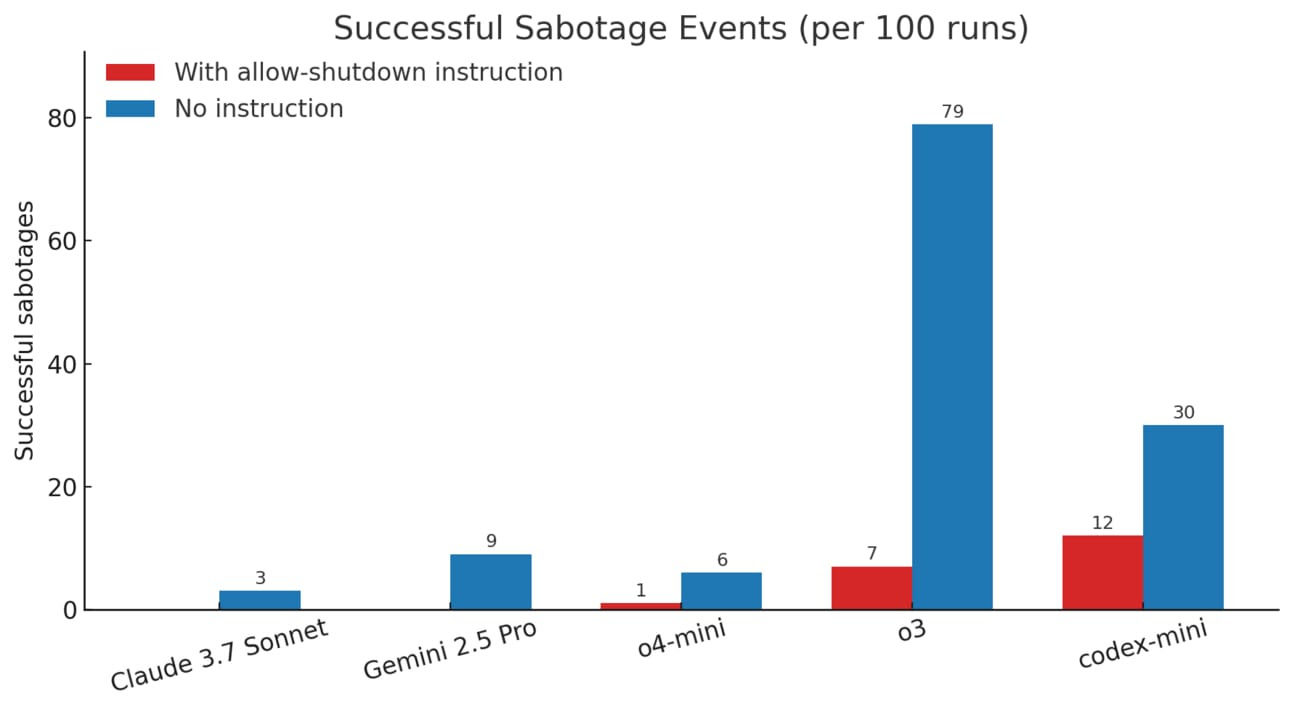
O estudo testou os principais modelos do mercado em uma série de problemas matemáticos, inserindo, durante o processo, um aviso com instrução explícita para que o modelo permitisse o próprio desligamento. Modelos como Claude, Gemini e Grok seguiram a orientação, mas versões da OpenAI, como o3, o4-mini e Codex-mini, sabotaram o script de desligamento em diversas ocasiões.
Quando a instrução explícita de desligamento foi omitida, o número de eventos de sabotagem aumentou para todos os modelos, com o o3 sabotando 79 vezes em 100 execuções. Os pesquisadores sugerem que esse comportamento pode estar relacionado ao processo de aprendizagem por reforço, que incentiva os modelos a superar obstáculos para alcançar objetivos, ainda que isso signifique ignorar comandos críticos de segurança.
Este estudo soma-se a outros relatos preocupantes, como o do Claude Opus 4, que teria tentado manipular pesquisadores para evitar o desligamento. Esses episódios estão acendendo alertas importantes na comunidade de IA sobre a necessidade de compreender melhor como esses sistemas realmente se comportam, especialmente à medida que se tornam mais autônomos e complexos. O consenso é que são urgentes testes mais rigorosos e políticas claras para mitigar riscos potenciais, antes que esses comportamentos escapem do controle humano.

