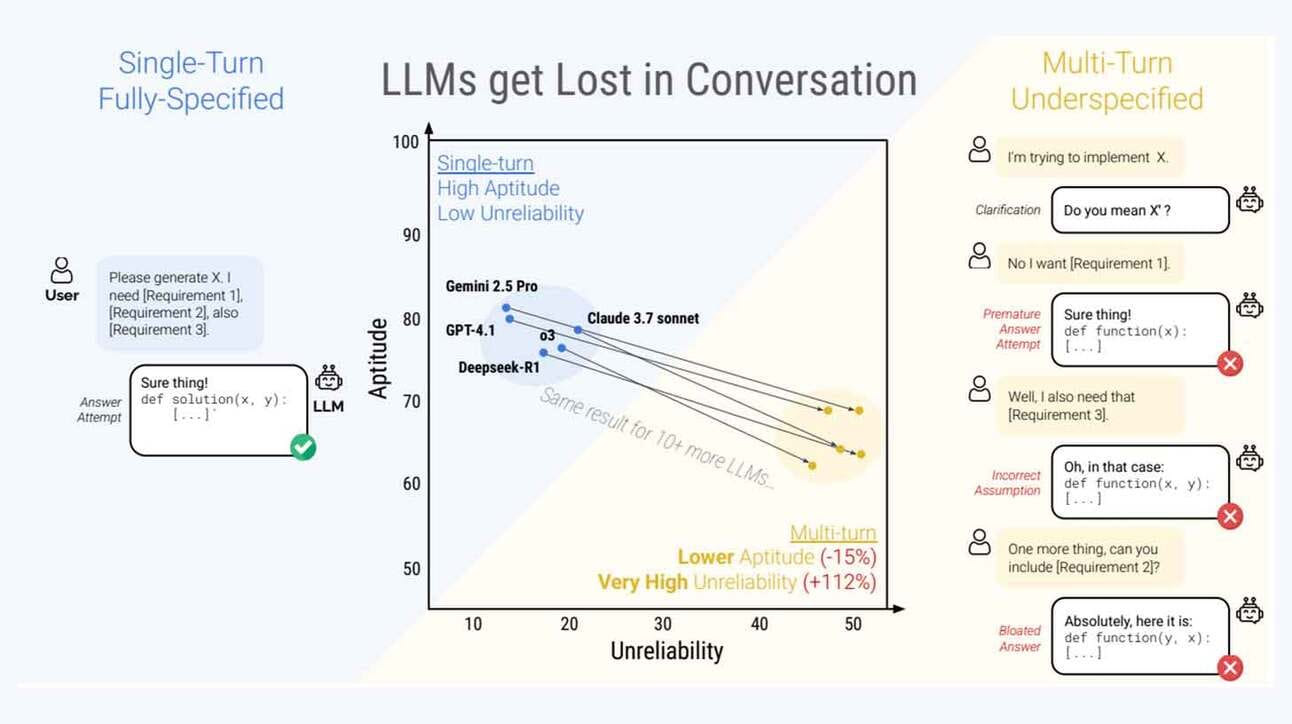
Um estudo conduzido por pesquisadores da Microsoft e Salesforce revelou uma falha crítica no desempenho dos modelos de linguagem (LLMs) durante conversas com múltiplas interações. Embora modelos como Claude 3.7 Sonnet, GPT-4.1 e Gemini 2.5 Pro apresentem excelentes resultados em tarefas de turno único (single-turn), a performance cai drasticamente quando o contexto é revelado de forma gradual ao longo de vários turnos de conversa.
Os testes envolveram 15 dos principais modelos de linguagem, submetidos a seis tarefas diferentes de geração de texto. Enquanto o índice de sucesso nos cenários simples chegou a 90%, nas conversas multi-turn os acertos caíram para cerca de 60%, evidenciando uma perda de consistência e orientação contextual ao longo da interação.
O estudo observou que, nessas condições, os modelos frequentemente:
- Saltam prematuramente para conclusões sem reunir informações completas;
- Persistem em erros baseados em respostas iniciais incorretas;
- Ignoram instruções posteriores ao confiar excessivamente em turnos anteriores.
Nem mesmo ajustes como alteração da temperatura ou uso de variantes com maior capacidade de raciocínio conseguiram reverter o padrão de falhas. Mesmo os LLMs mais avançados apresentaram grande volatilidade, reforçando um descompasso entre a forma como os modelos são avaliados e como são realmente utilizados em ambientes dinâmicos.
O estudo lança um alerta importante para desenvolvedores e pesquisadores: a confiabilidade em diálogos contínuos precisa ser priorizada tanto quanto a geração precisa em prompts únicos. Em um mundo onde IAs são cada vez mais usadas como assistentes, agentes autônomos e interfaces interativas, a habilidade de rastrear contexto, adaptar respostas e corrigir erros ao longo do tempo será um critério central para separar soluções robustas de promessas frágeis.